LLMs = Intelligence + Latency?
Whenever you see ✨ in the product you know there’s about to be some latency
— vicki (@vboykis) April 8, 2024
This lovely tweet by @vboykis is a great reminder of how LLMs are being perceived. GitHub copilot was one of the first to use the ✨ emoji to indicate that the response is being generated by an LLM.
Now ✨ emoji and purple-hued gradients on icons and websites have become synonymous with intelligence, but also latency (engineering jargon for calling something slow).
But, why? Why care about (LLM) latency?
It is well established in Human Computer Interface (HCI) research that, after any user action, if the output or change takes longer than one second to show, it is perceived as being slow 1Marginnote density1Ström, Matthew. 2024. “Density in Time.” https://matthewstrom.com/writing/ui-density/ - discusses how users perceive time density in user interfaces. ↩.
If the information is shown within 100ms, the time between action and outcome feels instant, for longer interactions within a second, having an animation or loading states help in reducing the user anxiety (or rather the impatience). Any interaction that takes longer than 10s makes the user lose interest.
In the early days of ChatGPT, it was common for users to wait for 4-5s to even start seeing any response from the model. But since day 1 of ChatGPT, they have been showing the decoded output of the model as it’s available, essentially stream native. In the model context protocol (MCP) implementation on Claude desktop, the text from tool-use is streamed well.
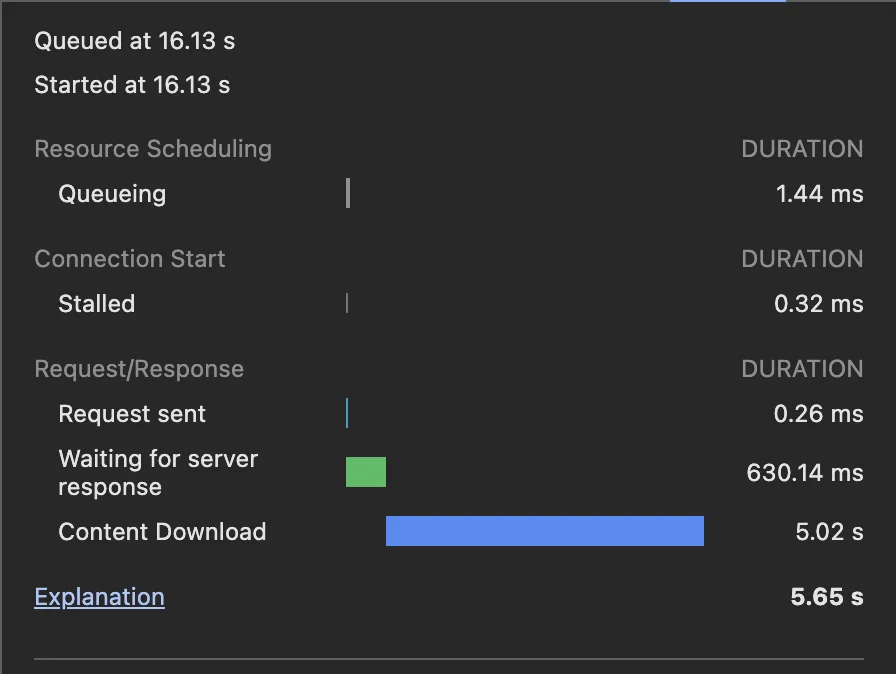
Now with the growth of applications offering LLM intelligence, some of them feel quite sluggish because they are slow. But in reality, if we breakdown the network timing of an LLM call, you will see a majority of the time is being taken to decode the output tokens (content download).
For the query - Give me a recipe for light roast v60 pour over, Claude takes 5s to complete the response but only 630ms for the first word (token) to be decoded.
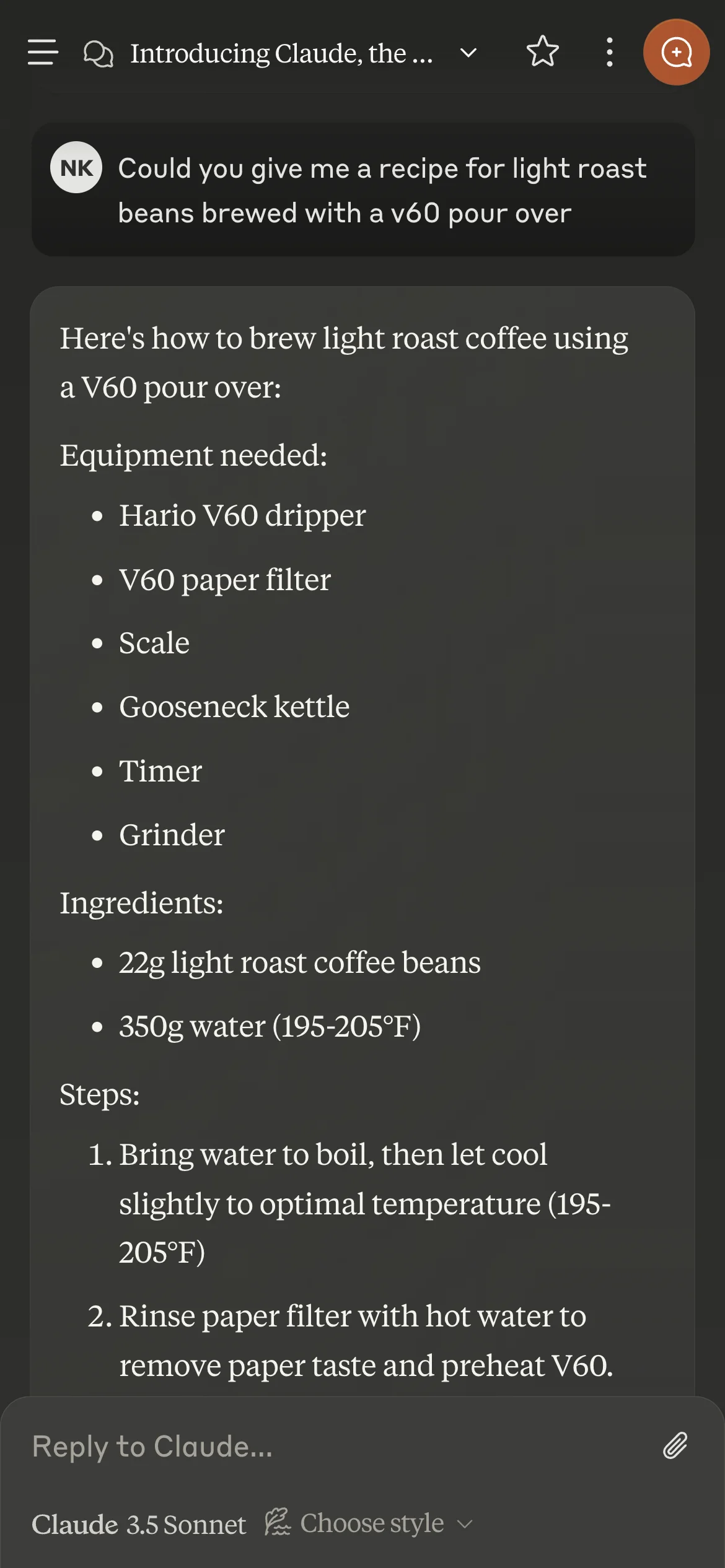
In case of chat applications, streaming the text is straightforward, user asks a questions and the LLM generates free-flowing text without any pre-defined structure.
However, in case of workflow driven cases where LLMs are generating some structured output, having the user wait for multiple seconds without any intermediate output is painful.
This reminds of the XKCD comic about compiling.

Keeping this in mind, let’s first establish some metrics that are good to keep track while offering LLM based applications.
Metrics to track for LLMs
- Time to decode the first token
- Total time for completion of text stream
- Total count of output tokens (they are more expensive than input tokens)
Structured output generation from LLMs
While generating structured output from LLMs (tool-use, JSON mode, function calling), the common UX paradigm is to wait for the entire output to be generated before showing it to the user. Since validation of the output is required to ensure it’s in the same schema as expected.
Having the ability to validate the decoded text as it’s being streamed can significantly elevate the entire experience, cutting down the waiting time.
Most popular LLM providers (OpenAI, Anthropic, AWS Bedrock) and open source LLM serving implementations (like vLLM, Triton, MLXServing) provide streaming tokens (text) as it’s generated by the model 2Marginnote streaming2Willison, Simon. 2024. “How streaming LLM APIs work.” https://til.simonwillison.net/llms/streaming-llm-apis - explains the technical implementation of streaming in LLM APIs using Server-Sent Events. ↩
enabled through server sent events [+see].
Let’s say we need to build an application that can digitize this image of a handwritten family recipe for rasam, into a structured format so that we can catalogue and show it on the UI shown below.


Why LLMs for this application?
We are going beyond just Optical Character Recognition (OCR) and transforming basis the information architecture defined on the UI. The following things can be implicitly handled by an LLM:
- Need to parse handwritten text
- The ingredients are scattered throughout the image, so we need to capture all of them
Now based on the sample UI above, we have a datastore of recipes that has the following schema:
Recipe:
- title: String
- ingredients: List of Ingredient
- instructions: List of String
Ingredient:
- item: String
- quantity: Integer|String
- unit: Enum (kg, g, l, ml, tsp, tbsp, cup, piece)Visualising streamed events from LLMs
While the model decodes tokens as per the schema, seeing the updates visually will give a better sense in understanding the importance of validating the structured output as it’s streaming. In the interactive widget below, click on start streaming button to start the decoding process and you can scrub through the timeline to see the changes in the data and how it looks on the UI.
Things to observe
- It takes about 4.5s to decode the entire schema but the important nuance is that it only takes 100ms to decode the first token 3Marginnote firsttoken3The time to first token (TTFT) is critical for user experience - it determines when users see the first sign of progress, significantly affecting perceived responsiveness. ↩.
- Based on the pseudo-UI above, we are decoding the JSON to show the UI elements in that order: title, ingredients, and finally, recipe.
SSE JSON Streaming Timeline
Watch how JSON validation changes as tokens stream in real-time
Accumulated JSON:
No JSON content yet...
If you run the image above through sonnet-3.5-v1 using the Anthropic SDK, It’s about 3000 input tokens and output would be about 300 tokens which is expected to be a JSON.
How to: Structured output generation
Now that we have established the way in which the data needs to be decoded, we need a way provide the expected schema to the LLM.
Tool use or JSON mode is a reliable way to generate this structured output. You can also achieve the same without using function calling by just mentioning in the prompt to fill the schema provided, with any instruction following model, it will save you some tokens when you don’t explicitly use function calling. But this tends to fail with smaller open-source models (Llama-3.1-7B) when the schema is complex with nested objects and arrays.
All developer SDKs (OpenAI, Anthropic, Bedrock, Gemini) expect the input for the schema for a function to be provided in OpenAPI JSON spec 4Marginnote openapi4OpenAPI Specification. 2024. Swagger. https://swagger.io/specification/ - the industry standard for describing REST APIs and function schemas. ↩, one of the standard ways to represent function schemas as JSON. Once the schema starting getting longer and has nested structures, writing it directly in OpenAPI spec becomes tiring and is quite error prone.
Pydantic has a great implementation for creating these tool schemas through their BaseModels 5Marginnote pydantic5Pydantic BaseModel. 2024. https://docs.pydantic.dev/latest/concepts/models/ - provides data validation and settings management using Python type annotations. ↩. All you need to do is call the BaseModel.schema_json() to get the OpenAPI compatible spec JSON through this. Later on in the post, we will also use the partial json validation that Pydantic offers.
# data_models.py
from pydantic import BaseModel, Field
from enum import Enum
from typing import List, Optional
class UnitEnum(str, Enum):
kg = "kg"
g = "g"
l = "l"
ml = "ml"
tsp = "tsp"
tbsp = "tbsp"
cup = "cup"
piece = "piece"
class Ingredients(BaseModel):
item: Optional[str] = None
quantity: Optional[int|str] = None
unit: Optional[UnitEnum] = None
class Recipe(BaseModel):
title: Optional[str] = Field(description="Title of the recipe", default=None)
ingredients: Optional[List[Ingredients]] = Field(description="List of ingredients", default=None)
instructions: Optional[List[str]] = Field(description="Instructions to make the recipe", default=None)Note: Note the use of
Optionalin all the fields. While partial validation of JSON, if any of required fields are missing then Pydantic raises an exception. This is a bit of a hack to get around it, but also note that this increases the number of tokens that are sent to the model.
Partial JSON validation
Pydantic has released support for validation of partial json, it’s based on their pydantic-core library and uses the jitter library written in rust for actually parsing the JSON.
We are using the from_json method defined in pydantic_core to perform our validation.
# partial_json_validation.py
from pydantic_core import from_json
from data_models import Recipe
def validate_partial_json(streamed_text: str):
if streamed_text != "":
validated_dict = from_json(streamed_text, allow_partial=True)
recipe = Recipe.model_validate(validated_dict)
return recipe
return NoneDecoding json partially involves keeping track of the opening and closing of quotes, different types of brackets for objects and arrays in a stack and then checking which of those match. I tried replicating this in JS but it there are a lot of cases that need to be handled. The jitter library is quite well written, and code base is fun to read through.
Now, to perform this validation on the stream, on every content-block streamed from the LLM API, call the validate_partial_json function.
# main.py
from pydantic_core import from_json
def validate_partial_json(streamed_text: str):
if streamed_text != "":
validated_dict = from_json(streamed_text, allow_partial=True)
recipe = Recipe.model_validate(validated_dict)
return recipe
return None
def validate_stream(time_between_checks = 0.003):
streamed_text = ""
start_time = time.time()
last_check = time.time()
# This is the stream from anthropic
for response in stream._raw_stream:
if response.type == "content_block_start":
continue
if response.type == "content_block_delta":
streamed_text += response.delta.partial_json
elapsed_time = time.time() - start_time
last_check_time = time.time() - last_check
# check if it's been time between checks since last check
if last_check_time >= time_between_checks:
last_check = time.time()
validated_json = validate_partial_json(streamed_text)
if validated_json is not None:
yield validated_json
print(elapsed_time)
validated_json = validate_partial_json(streamed_text)
yield validated_jsonIn the code, there is a parameter time_between_checks to check how frequently to perform the partial JSON validation, this is to ensure we are not blocking the CPU constantly by doing the validation and having enough decoded tokens.
Structured schema generation checklist
LLMs always generate the next token, so, if a JSON object key is being currently decoded, we know that the value of that key will be decoded next.
- Structure your schema in a way that first UI component to render is being decoded first, like in the recipe example, we decode the title.
- Arrays and nested objects are decoded as is.